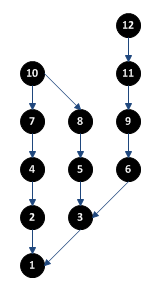
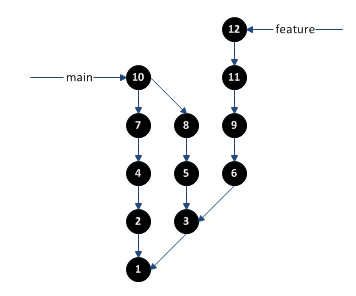
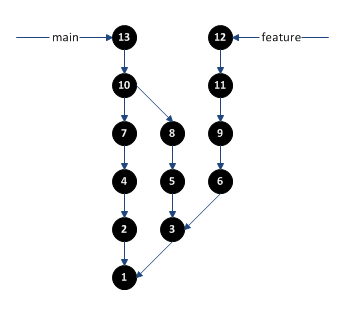
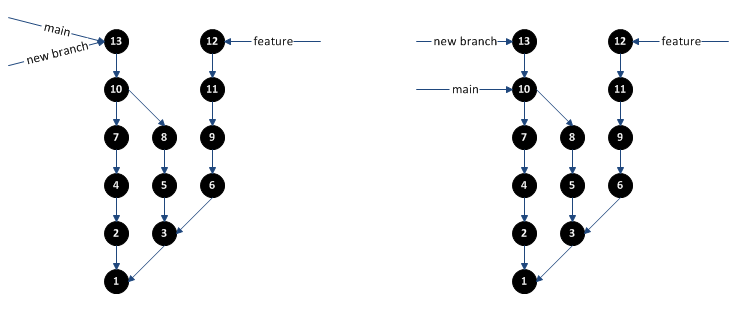
Recently, my manager mentioned he was trying to decide out how to properly differentiate between software engineers and programmers. We didn’t have much time to discuss it, but another nearby manager suggested that engineers designed software that could then be implemented by programmers. The implication being that the programmer was just following directions, whereas the engineer was actually doing the “thinking” behind the design. This view is very common among larger, “old-school” companies with a traditional waterfall process history, where product development is divided into discrete steps: plan, design, implement, test, release, maintenance.
After 35+ years of professional programming, I knew this wasn’t an accurate description about how real software development works, but I hadn’t really sat down and thought about it enough to figure out why. It was usually just a question of what title to put on someone’s business card and didn’t have any real-world impact on anyone’s actual work. This recent conversation, however, caught my attention and led me to think about this issue in more detail.
I’m going to jump straight to the end and state up front that I have concluded that there really isn’t any distinction between a programmer, software developer, and software engineer. Now, let me explain my rationale.
Several years ago, I came across an article written by Jack W. Reeves called What Is Software Design? This article was a revelation for me. The basic premise of the article is that software is design. This simple concept resolves so many issues with the way many companies have treated the software development process. There is more information in the article then can be explained here, but the basic idea is that programming, testing, and debugging are all integral parts of the design process. Interestingly, the agile practice of Scrum include aspects of this without really discussing it in the same terms. In its theoretically ideal implementation, Scrum teams consist of several skilled generalists, who are each capable of design, implementation, testing, debugging, etc. These are all part of the same process.
Anyone who’s actually tried to produce a complete written detailed design suitable to be given to an entry-level “programmer” to implement without them having to really understand the design knows this doesn’t work. It has never worked, but companies keep thinking they can do it. To produce a design that can be implemented in a “paint-by-numbers” fashion would require that almost every line of code be described in advance, at which point you have essentially written the software. This is analogous to asking Stephen King to write detailed enough instructions for someone else to write one of his books. As soon as you start abstracting the ideas even a little, the book would become the writer’s book, not a Stephen King book. The same thing happens with software—at any practical level of up-front design, the resulting implementation is actually designed by the individual programmers and the resulting source code is effectively the final detailed design.
It is still important to do high-level architecture and design up front, but the software itself is the ultimate detailed design. I equate software source code to blueprints or schematics. The actual manufacturing process is performed by the compiler and linker, following the detailed design in the source code.
This leads to the obvious conclusion that anyone involved in the writing of software, whether they are called programmers, developers, or engineers, are actually software designers. For those who insist that there be some distinction, it would be reasonable to consider these titles as different points along a continuum of software development. A “programmer” is typically a junior developer, who focuses on designing smaller, self-contained portions of the software. An “engineer” would be at the other extreme, and is responsible for larger component or product-wide design. Additionally, there many be a separate “architect” who focuses on system-level design and the interactions between major components. Each of these individuals is designing parts of the product, but the scope of their design is limited based on their experience and knowledge.
![computesataricollectionvol2_0000[1]](https://doug-wheeler.com/wp-content/uploads/2016/05/computesataricollectionvol2_00001.jpg)