Moving from a traditional source control system like Perforce or Subversion to Git seems like it shouldn’t be that hard. In fact, Git is supposed to be very easy to use, so why is it that when I first started using Git, I kept getting tripped up? I had read Joel Spolsky’s Mercurial tutorial (not exactly like Git, but close enough) and thought I understood it. Joel also made it very clear that there was an unlearning process that had to take place, but I didn’t realize how much I needed to unlearn.
Git tries to use familiar concepts in an effort to make the transition easier, but I think it really does more harm than good. You end up with a situation where familiar terms are used to describe things that are similar only at a very superficial level. It doesn’t take long for the differences to trip you up.
I’m not going to focus on the differences between centralized vs. distributed version control systems (that is covered in other places and is fairly straightforward). I’m going to concentrate on which “old” concepts you need to unlearn, specifically branch, changeset, head, and checkout. Whatever you think these terms mean is very likely wrong in the world of Git. Read on and be enlightened.
COMMITs
The fundamental unit of data in Git is the commit. In most systems, when you commit changes, those changes are packaged into a changeset or something similar. Whenever you commit changes to Git, Git effectively creates a snapshot of your entire workspace in its current state. To save space, these snapshots only contain the delta between a “parent” commit and the new commit. Each commit contains a link to its parent commit. In the case of a merge, the commit contains a link to each of the two parent commits used to create this one. Other than the very first commit, each commit has one or two parents.
So, a Git repository is essentially just a collection of commits connected by backward links to their parent commits. Here’s an example with 12 commits and the backward links from each to its parent:
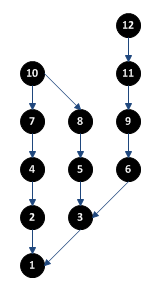
Just to orient yourself, the oldest commits are at the bottom and the newest are at the top (some documentation/software shows this inverted, or horizontally).
Perhaps you’ll be surprised to learn that from Git’s perspective, this diagram does not show any branches. Your first reaction may be “of course it does!” In fact, this figure shows three commit history paths, but in Git parlance, these are not called branches.
Branches
So, what is a Git branch? A branch is simply a named pointer to a commit. Let’s add a few to our example:
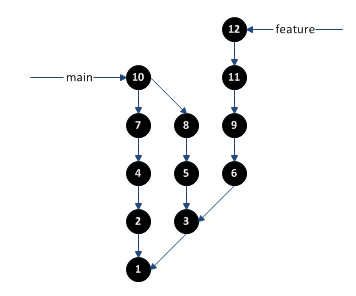
We now have two branches, “main” and “feature”. The hardest part to understand is that these branches are just pointers to a single commit. They don’t refer to the entire line of changes. For example, although there are two paths leading to “main”, there is no record of which of those was the main branch. Branches can be created, destroyed, and moved without affecting any of the commits. You can also have several branches pointing to the same commit. These combine to allow for easy changes to the branch names, the ability to “retroactively” create a new branch, and more.
You can also see in this diagram that there is not a branch corresponding to commit 8. Once you merge two branches, you can safely delete the extra branch without affecting the repository (other than the branch “label” disappearing). You can even recreate the branch at the same point in the future if you want. The only thing to be aware of, is that unreferenced commits (those without a branch label or a child commit) will eventually be deleted (Git has a built-in garbage collector). So, if we move the “feature” branch to commit 11, then commit 12 would eventually be garbage collected. Normally Git waits some time before deleting these orphaned commits to allow for situations where the user is simply moving branches around and has only temporarily orphaned a commit.
Let’s take a look at a very common situation. Let’s say you are developing a new feature but forgot to create a new branch for your work and accidentally commit your changes to the main branch. After your commit, the repository looks like this:
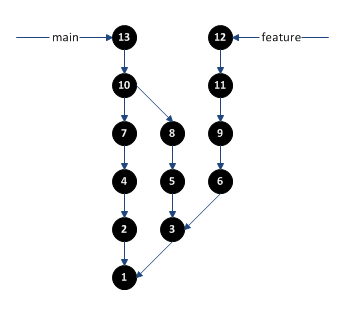
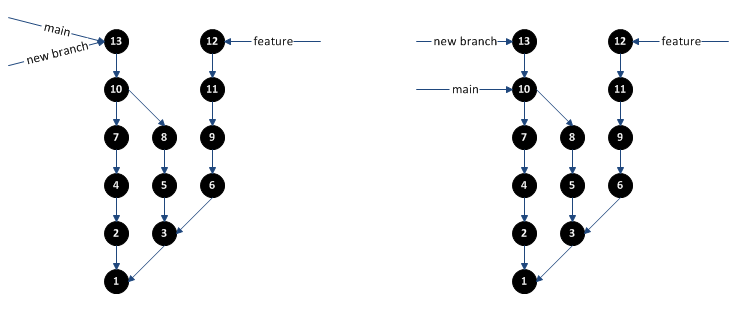
where your new changes were committed as commit 13. This can easily be fixed by creating a new branch at commit 13, then moving the “main” branch back to commit 10.
Head
The head is a pointer to your “current” branch. So, the head is a pointer to a branch, and the branch is a pointer to a commit:
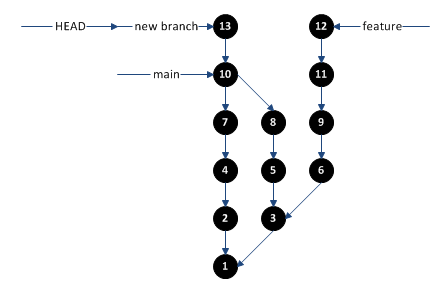
The head is used primarily when you commit changes. When you commit changes, Git follows the head pointer to the branch, then follows that to a commit. It then creates a new commit as a child of that one and moves the branch to the new commit:

Since the head points to the branch, it effectively moves with it. If you want to change the head explicitly, you can do that by doing a checkout.
Checkout
Performing a checkout on a branch does two things: it moves the head pointer to that branch and updates your local workspace files to match the corresponding commit snapshot. If you wanted to switch to the “feature” branch, you can do a checkout of that branch to move the head pointer there and update your local workspace files to match the associated commit snapshot:
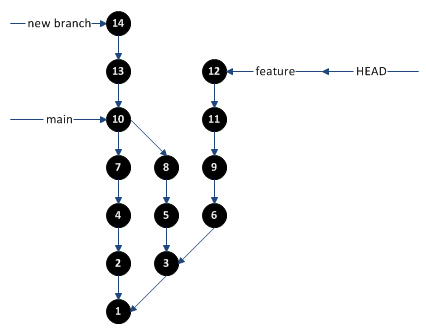
Summary
The key points are:
- Each commit creates a snapshot that effectively captures the state of your local workspace at the time of the commit.
- A branch is simply a pointer to a commit.
- The head is a pointer to the current branch.
- Checkout moves the head to a new branch and updates your workspaces to match the corresponding commit snapshot.
It is also important to be aware that some Git tools introduce some complications into this. For example, the process of moving a branch pointer (using a reset command) may cause a checkout at the same time. There are usually command options to control these interactions. Another concept that you’ll have to deal with (which isn’t covered here) is how uncommitted changes to local files are handled during these operations.
The best part of Git is that you can try out commands on your local repository before pushing your changes to the server. Even if you completely mess up your local repository, you can simply throw it out and get a fresh copy from the server.